Introduction to neptune.ai#
Neptune consists of:
- A Python API (neptune + integrations) for logging and querying model-building metadata.
- A web app (app.neptune.ai ) for visualization, comparison, monitoring, and collaboration.
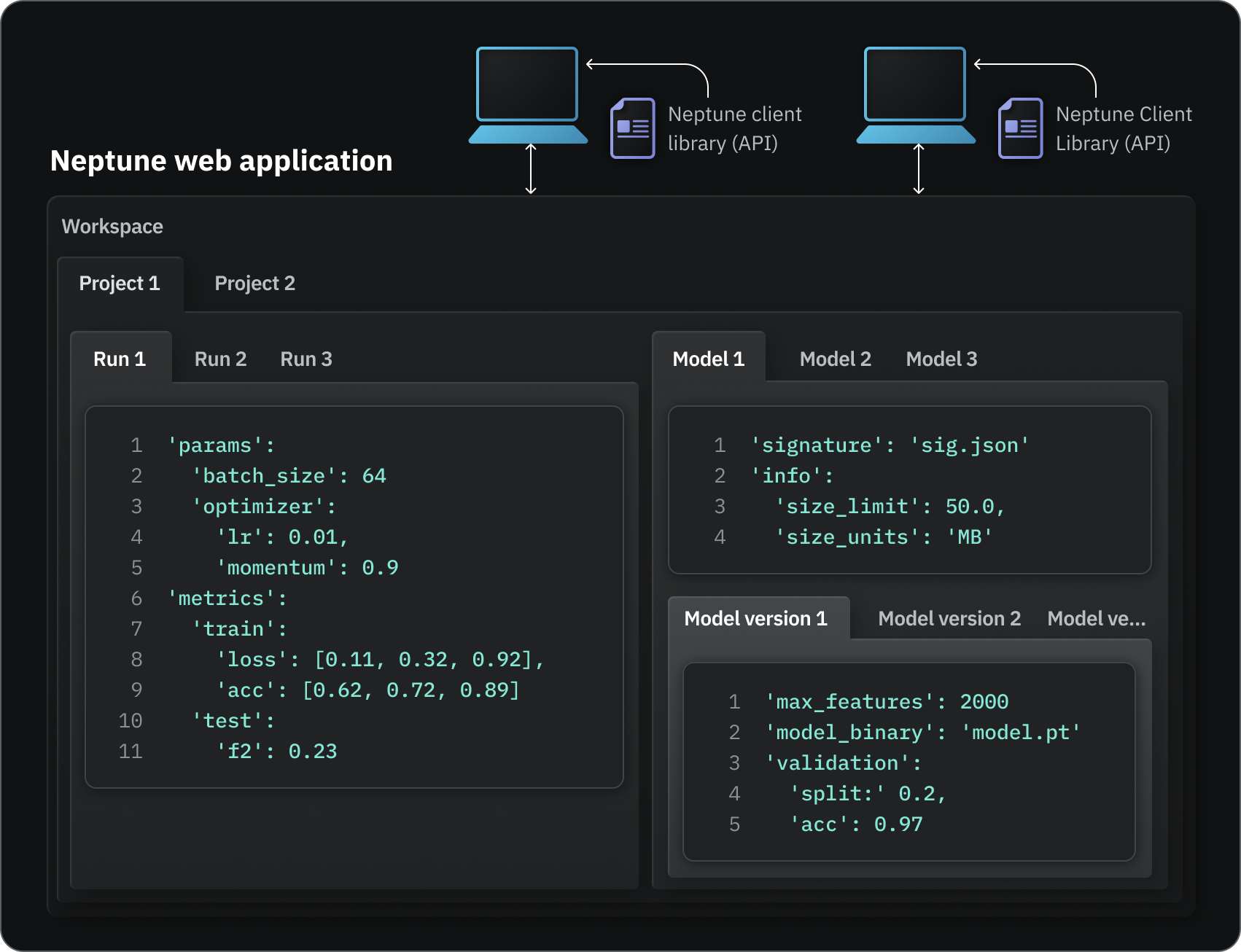
You can have a workspace for each team or organization that you're working with. Within a workspace, you can create a project for each ML task you're solving.
Your project can contain metadata organized per run, model, or task.
Examples of ML metadata Neptune can track
Experiment and model training metadata:
- Metrics, hyperparameters, learning curves
- Training code and configuration files
- Predictions (images, tables)
- Diagnostic charts (Confusion matrices, ROC curves)
- Console and hardware logs
Artifact metadata:
- Paths to the dataset or model (Amazon S3 bucket, filesystem)
- Dataset hash
- Dataset or prediction preview (head of the table, snapshot of the image folder)
- Feature column names (for tabular data)
- When and by whom an artifact was created or modified
- Size and description
Trained model metadata:
- Model binaries or location of your model assets
- Dataset versions
- Links to recorded model-training runs and experiments
- Who trained the model
- Model descriptions and notes
- Links to observability dashboards (like Grafana)
For a complete reference of what you can track, see What you can log and display.
How does it work?#
import neptune
from sklearn.datasets import load_wine
...
run = neptune.init_run()
data = load_wine()
X_train, X_test, y_train, y_test = train_test_split(...)
PARAMS = {"n_estimators": 10, "max_depth": 3, ...}
run["parameters"] = PARAMS
...
test_f1 = f1_score(y_test, y_test_pred.argmax(axis=1), average="macro")
run["test/f1"] = test_f1
Integrations with the ML ecosystem
Skip the manual logging with our integrations.
You can usually create a Neptune logger or callback that you pass along in your code:
import neptune
from neptune.integrations.tensorflow_keras import NeptuneCallback
neptune_run = neptune.init_run()
# Create a Neptune callback and pass it to model.fit()
model.fit(
...
callbacks=[NeptuneCallback(run=neptune_run)],
)
The above code will take care of logging metadata typically generated during Keras training runs.
For more, see Integrations.
What do I need in order to use Neptune?#
To use the SaaS (online) version of Neptune, you need an internet connection from your system.
To set up logging and perform queries through the client library (API):
- You or your team should have a working knowledge of Python.
- You do not need extensive command-line experience, but you should know:
- How to set environment variables in your system, to store Neptune credentials more securely.
- How to open and enter commands through a terminal, so you can use the Neptune command-line interface tool to synchronize local data with Neptune servers.
Neptune self-hosted
You can also install Neptune on your own infrastructure. For details, see Self-hosted Neptune.
You can do the following without coding or technical expertise:
- Explore, sort, and organize the logged metadata in the web app.
- Edit details such as names, descriptions, and tags.
- Create models in the model registry.
- Manage model stage transitions.
- Manage workspaces, projects, members, and permissions.
- Create and manage service accounts.
- Trash and delete data.